python zhihu-spider

Xzhah
11月 24, 2017
这个爬虫并不是我写的,是找一个师傅要的。自己看懂了过后把代码贴上来加上自己的一些领悟。
* 成果
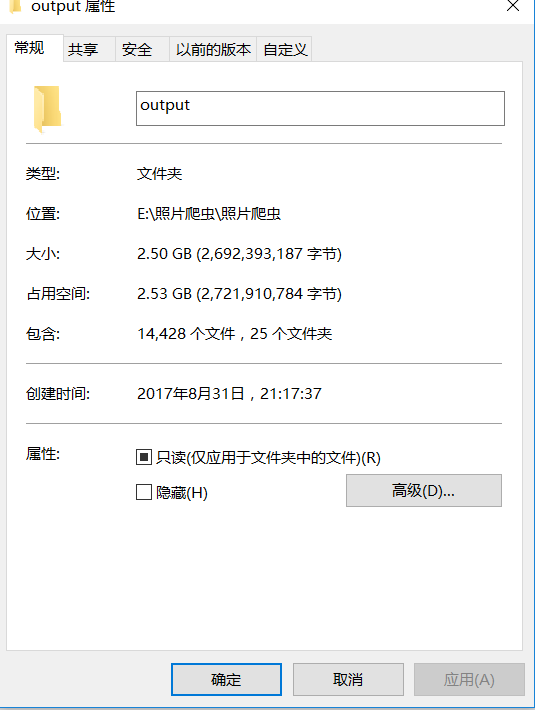
* 完整代码
1 | # -*- coding:utf-8 -*- |
* 翻页
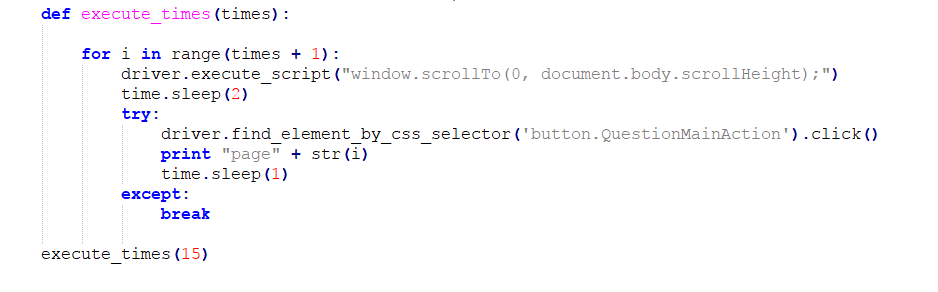
这部分是不断跳至页面最底部点击查看更多回答
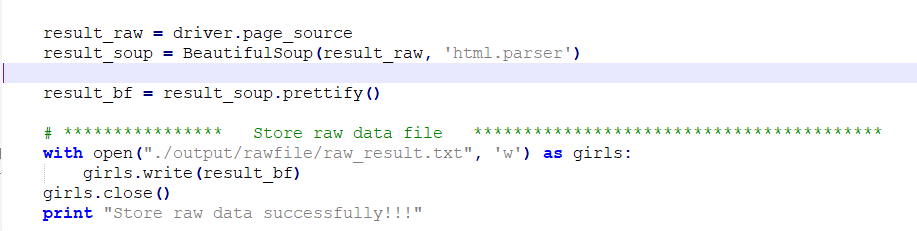
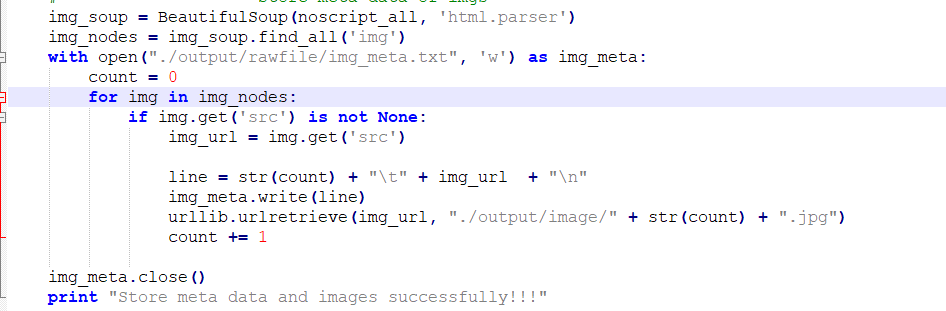
* 读入网页源码并写入raw_result.text
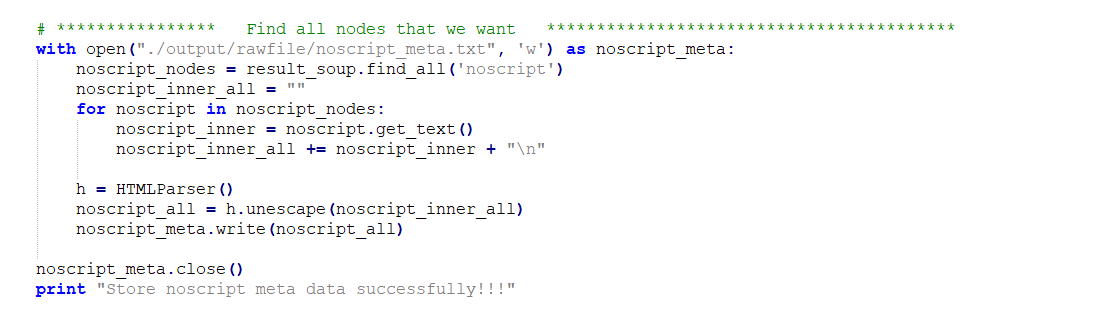
* 筛选noscript段(img的部分)
* 下载图片
* 感悟
日渐消瘦